4 . fejezet Induktív statisztika
Ebben az alfejezetben röviden, az alapkoncepciókra fókuszálva bemutatjuk a statisztika induktív ágát. Már volt róla szó, hogy az induktív statisztika jellemzője, hogy tekintettel van a mintavételi helyzetre (azaz arra, hogy mi csak egy részét ismerjük azon sokaságnak, melyre a kérdésünk irányult): azzal foglalkozik, hogy hogyan lehet pusztán a mintában lévő információ alapján mégis a sokaságról nyilatkozni. Innen a módszer neve: indukció a.m. következtetés, tudniillik következtetés a mintából a sokaságra.
Elsőként röviden megismételjük, és pár fontos részlettel kibővítjük a mintavételi helyzettel kapcsolatos ismereteinket; ezt követően nagyon tömören, az alapelvekre szorítkozva bemutatjuk az induktív statisztika két nagy területét: a becsléselméletet és a hipotézisvizsgálatot. A becsléselmélet azzal foglalkozik, hogy egy sokaságot jellemző paramétert, például a sokaság átlagát pusztán a minta alapján ,,megtippeljünk’’ (valamilyen szempontok szerint a lehető legjobban). A hipotézisvizsgálat ennek bizonyos értelemben az ikertestvére: célja, hogy a sokaság valamely jellemzőjére tett állítások – például a sokaság átlaga egy adott szám – helyességét ,,megtippeljük’’ pusztán a minta alapján.
4.1 A mintavételi helyzet és következményei
Ahogy már megbeszéltük, mintavételi helyzetről akkor beszélünk, ha a sokaságnak (amire, definíció szerint, kutatási kérdésünk vonatkozik), csak egy részét tudjuk megfigyelni. Ezt a megfigyelt részt nevezzük mintának. Szintén volt róla szó, hogy a mintavételi helyzet jelentősége a biostatisztikában hatalmas: nem csak azért, mert egy sor gyakorlati esetben bár a sokaság elvileg teljeskörűen megfigyelhető lenne, de erre gyakorlati okok (költség, időigény stb.) miatt nincs mód, hanem azért is, mert biostatisztikában tipikusak az olyan kérdések, melyek fiktív, végtelen sokaságra vonatkoznak (például: ,,Egy új vérnyomáscsökkentő gyógyszer-jelölt valóban csökkenti a vérnyomást?’’). Ilyen esetekben bármennyi megfigyelést is végzünk, az szükségképp minta lesz.
Adódik tehát a feladat, hogy annak ellenére nyilatkozzunk a sokaságról, hogy mi csak egy részét ismerjük. Nagyon sokan ezen a ponton valószínűleg azt gondolják, hogy ez lehetetlen feladat – valóban, példának okáért, ha 1000 elemből csak 999-et ismerünk, akkor elvileg bármennyi lehet a sokaság (mind az 1000 elem) átlaga, akármik is voltak a minta elemei.
Az a megállapítás azonban, hogy ,,semmit nem tudunk mondani’’ a sokaságról, szerencsére túlzás. A helyes megfogalmazás az, hogy biztosat nem tudunk mondani a sokaságról de valószínűségi kijelentéseket továbbra is tudunk tenni! Ha ugyanis megfelelően történt a mintavétel (erre még visszatérünk), akkor már a minta is elárult valamit a sokaságról, tudni fogunk valamit azokról a valószínűségi törvényszerűségekről, melyek az ismeretlen elemek viselkedését (is) áthatják. Ez pedig lehetővé fogja tenni, hogy ugyan csak sztochasztikus értelemben, de azokról is nyilatkozzunk.
Az tehát nem igaz, hogy semmit nem tudunk mondani a sokaságról, de azzal valóban együtt kell élnünk, hogy az induktív statisztikában – szemben a deskriptívvel – már csak bizonytalansággal terhelt állításokat tudunk tenni. Szerencsére azonban arra is képesek leszünk, hogy e bizonytalanság mértékét magát is becsüljük (persze ismét csak: bizonytalansággal terhelten).
Nyilvánvaló, hogy bármilyen induktív statisztikai feladatot is kell megoldanunk, ahhoz csak a mintában lévő információt tudjuk felhasználni (ez épp a minta definíciója). Márpedig ha csak a sokaság egy részét (a mintát) ismerjük, akkor bármilyen, mintából számolt jellemző két dologtól fog függeni:
- a jellemző sokaságbeli értékétől,
- attól, hogy konkrétan hogy választottuk ki a mintát.
Példának okáért, egy minta átlagát két dolog fogja befolyásolni: a sokaság átlaga (ha ez nagyobb, akkor várhatóan egy minta átlaga is nagyobb lesz) és az, hogy konkrétan melyik elemeket választottuk ki a sokaságból (adott sokasági átlag mellett is választhatunk – tökéletesen véletlen mintavétel mellett is! – pont kisebb, és pont nagyobb elemeket is).
Mi értelemszerűen csak az elsőre vagyunk kíváncsiak, de sajnos a második hatása elvileg is kiküszöbölhetetlen. Bármilyen módszert is találunk ki arra, hogy a mintából hogyan következtessünk a sokaságra, teljesen biztos, hogy annak a végeredménye mintáról-mintára változni fog, azaz függeni fog attól, hogy konkrétan ,,hogyan nyúltunk bele a sokaságba’’, konkrétan milyen mintát vettünk. Ezt a jelenséget hívjuk mintavételi ingadozásnak. A szerencse épp az lesz, hogy ez a mintavételi ingadozás követni fog bizonyos (valószínűségi) törvényszerűségeket, így bár a fenti miatt elkerülhetetlenül hibázhatunk a következtetésnél, de annak természetéről fogunk tudni nyilatkozni.
Amit nagyon fontos megérteni, hogy az előbb említett ,,hibázás’’ alatt nem arra kell gondolni, hogy valamilyen értelemben rosszul vesszük a mintát. Ha egy 1000 fős sokaságból veszünk egy 30 fős mintát a sokasági átlag becslésére, akkor előfordulhat, mégpedig a legtökéletesebben véletlen mintavétel mellett is, hogy épp a 30 legkönnyebb embert választjuk ki a sokaságból. Természetesen, ha rosszul veszünk mintát (például akár tudattalan módon is, de a soványabb embereket szólítjuk meg a kérdőívvel, hogy ne hozzuk zavarba a megkérdezetteket), akkor elképzelhető, hogy ennek megnő a valószínűsége, de akkor sem nulla ha tökéletesen véletlen a mintavétel.
Csak épp – és itt jön a lényeg – extrém kicsi! Ha tényleg tökéletesen véletlen a mintavétel, azaz minden sokasági alanynak azonos esélye van a mintába kerülésre, akkor annak a valószínűsége, hogy pont a 30 legsoványabbat választjuk ki épp \(1/\binom{30}{1000}\approx 4\cdot 10^{-56}\)%. Így értendő az, hogy a hiba valószínűségszámítási úton, ,,sztochasztikusan’’ limitálható: nem tudjuk kizárni, hogy ilyen – hatalmas méretű – torzítás keletkezzen a mintából következtetés hatására de meg tudjuk mondani, hogy ennek mennyi a – szerencsére igen kicsi – valószínűsége. Az ilyen okokból fakadó hibázást nevezzük mintavételi hibának.
Nem csak olyan hiba van azonban, ami az – elkerülhetetlen – mintavételi ingadozásból adódik. Véthetünk hibát alullefedéssel és túllefedéssel (azaz a minta pontatlan körülírásával), véthetünk definíciós hibát a kérdéseknél, hibát az adatkódolás során, a végpont megválasztásánál stb. stb., de ami még fontosabb, hogy véthetünk hibát a minta kijelölésével (amennyiben a minta valójában nem reprezentatív a sokaságra nézve, lásd az előbbi példát a személyes megkérdezéses testtömeg-vizsgálatról), vagy épp megfigyeléses vizsgálat esetén a confounding-gal. Ezeket – tisztán statisztikai úton nem olyan könnyen kézben tartható – hibákat nevezzük egységesen nem-mintavételi hibáknak.
4.2 Becsléselmélet
A becsléselmélet az induktív statisztika egyik fő ága, feladata valamilyen sokasági jellemző értékének minta alapján történő megbecslése. A ,,becslés’’ szó használata azért indokolt, mert az előbb kifejtettekből világos, hogy mintavételi helyzetben csak valószínűségi jellegű kijelentések tételére van mód.
A sokasági jellemzőt teljesen általánosan11 értjük (ha nem specifikáljuk közelebbről, akkor általában \(\theta\)-val jelöljük), bármilyen, a sokaság ismeretében számszerűen meghatározható értéket jelenthet (például a sokaság átlagát, szórását, valamilyen tulajdonsággal rendelkező elemeinek az arányát stb.). Egy tipikus példa a sokaság átlagának/várható értékének becslése12. Egy teljesen természetes gondolat, hogy ezt a jellemzőt a minta átlagával igyekezzünk megbecsülni.
Ez a naiv ,,tipp’’ is mutatja már, hogy mit értünk precízen becslés alatt: egy olyan függvényt (neve becslőfüggvényt vagy egyszerűen becslő), melynek bemenetül a minta elemeit kell megadni, eredményként pedig kidobja a becslést az ismeretlen sokasági jellemzőre. Egy \(\theta\) sokasági jellemző becslőfüggvénye tehát egy \[ \widehat{\theta} = f\left(x_1,x_2,\ldots,x_n\right) \] függvény. (A becsült értéket a statisztikában általában is kalappal jelöljük.) Az előbbi naiv példánk azt jelenti, hogy ha a becsülni kívánt jellemző a sokasági várható érték (\(\theta=\mu\)), akkor reményeink szerint arra jó becslő lesz az \[ f\left(x_1,x_2,\ldots,x_n\right)=\frac{\sum_{i=1}^n x_i}{n}=\overline{x} \] függvény. Ahogy már korábban is megállapítottuk, ennek értéke két dologtól fog függeni: a \(\mu\) értékétől (a valódi sokasági jellemzőtől), és attól, hogy konkrétan milyen mintát vettünk. Ez utóbbi hatás miatt természetesen a becslőfüggvény eredménye minden egyes mintán más és más lesz, mintáról-mintára ingadozik. Visszatérve az egyszerű példánkra az 1000 elemű, véges sokaságból történő átlagbecslésre: kaphatjuk, mintavételtől függően, a legkönnyebb 30 ember átlagát is becslésként, és a legnehezebb 30 átlagát is. (És természetesen egy sor értéket a kettő között.) De, amint már ott is megállapítottuk, ezen extrémumok valószínűsége kisebb, a közbülső (és ilyen módon a valósághoz közelebb álló) értékeké pedig – szerencsére – nagyobb. Más szóval arra jutottunk, hogy a becslőfüggvény értékeinek is van egy eloszlása: meg lehet adni, hogy adott tartományba eső becslést mekkora valószínűséggel adnak. Ezt nevezzük mintavételi eloszlásnak.
Érdemes ezt egy szimulációval is megnézni! Vegyünk ugyanabból a sokaságból, melyet itt eloszlásával adtunk meg (\(\mathcal{N}\left(30,70\right)\)), 10 darab 30 elemű mintát, majd mindegyiknek számoljuk ki az átlagát:
## [1] 68.15772 69.99507 70.61736 68.56484 66.69521 72.13443 69.86652 72.24791
## [9] 71.83016 66.54268Látszik, hogy – noha a sokaság állandó, és így a várható értéke is állandó, fixen 10 – a minták átlaga, tehát a sokaság várható értékének mintából becsült értéke ingadozik.
Elég sok ilyen szimulációt végezve, ez az ingadozás jól feltérképezhető (4.1. ábra).
## [1] 70.00478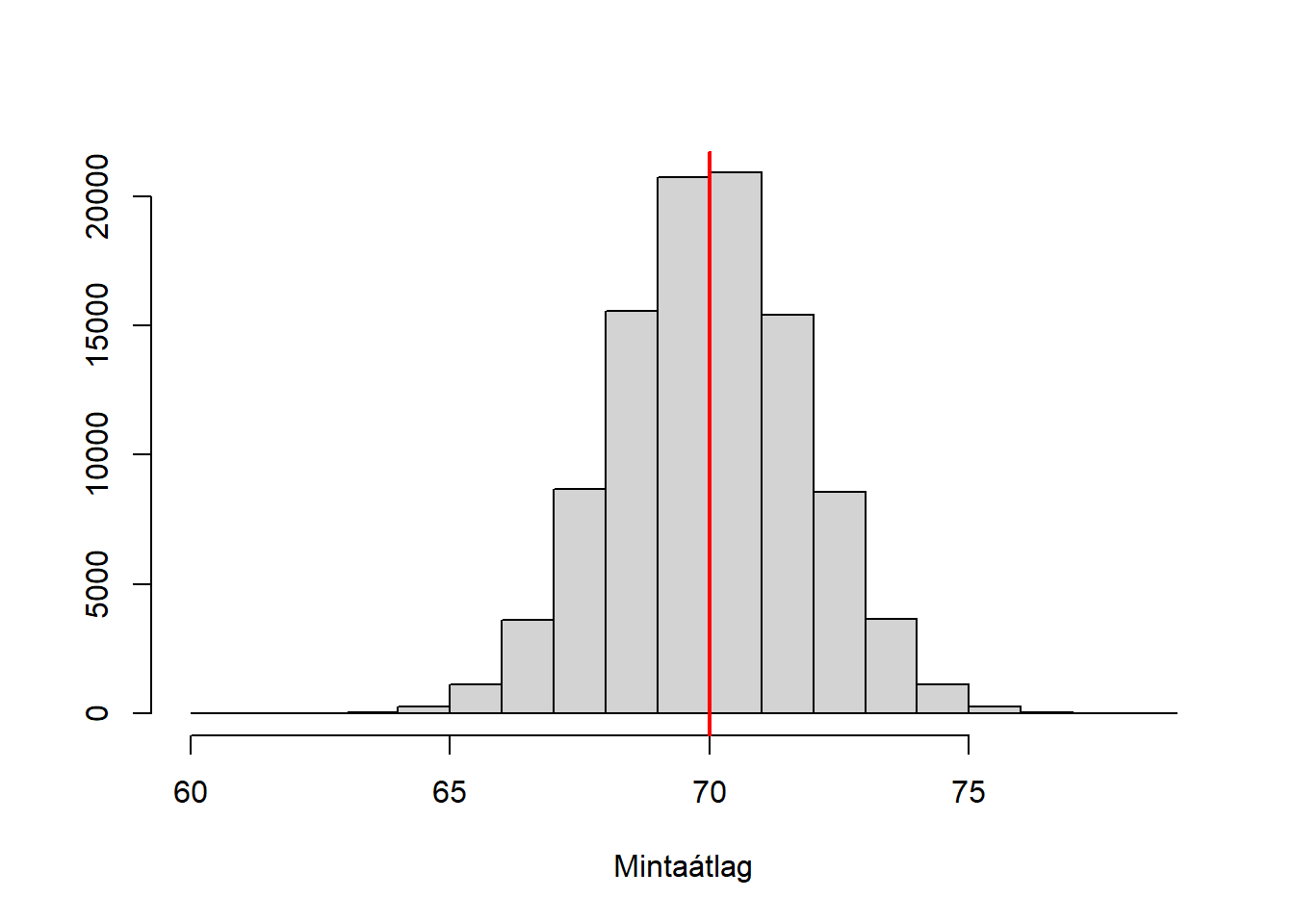
Ábra 4.1: A mintaátlag mintavételi eloszlásának meghatározása szimulációval, normális háttéreloszlás mellett.
Ilyen módon további fontos kérdések is vizsgálhatóak, például megnézhetjük, hogy a becsült érték ingadozása hogyan függ a mintanagyságtól (4.2. ábra).
res <- replicate( 100000, mean( rnorm( 30, 70, 10 ) ) )
plot( density( res ), ylim = c( 0, 0.7 ), main = "", ylab = "", xlab = "Mintaátlag" )
res50 <- replicate( 100000, mean( rnorm( 50, 70, 10 ) ) )
lines( density( res50 ), col = "blue" )
res300 <- replicate( 100000, mean( rnorm( 300, 70, 10 ) ) )
lines( density( res300 ), col = "orange" )
abline( v = 70, col = "red", lwd = 2 )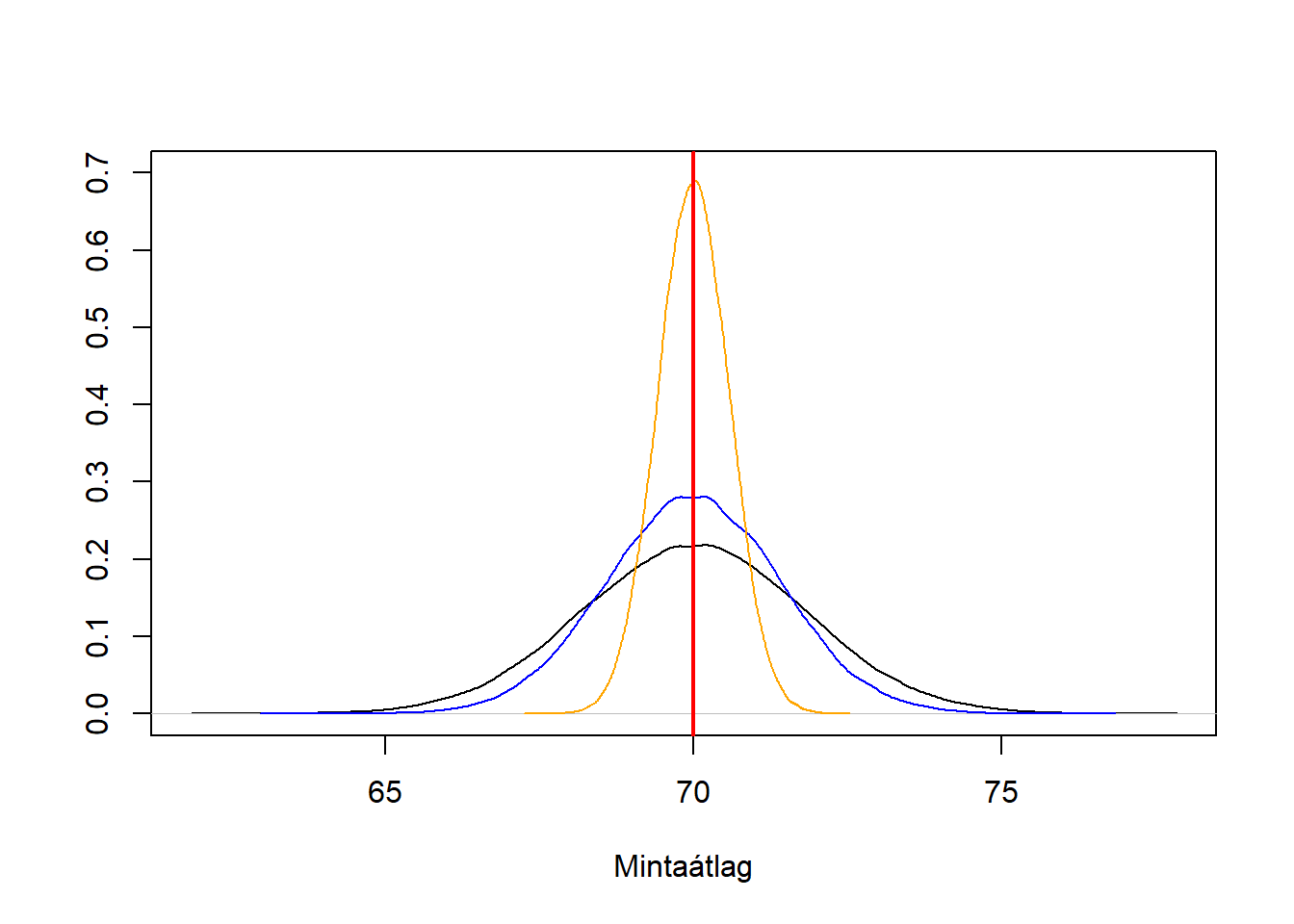
Ábra 4.2: A mintavételi eloszlás függése a mintanagyságtól.
Az ilyen vizsgálatok (szokták ezt Monte Carlo szimulációnak is nevezni) könnyen kivitelezhetőek, és megfelelő számítási kapacitás mellett bonyolult problémák kezelésére is alkalmas. Hátránya viszont, hogy nem kapunk analitikus eredményt (tehát a mintavételi eloszlást nem kapjuk meg matematikai képlettel felírt függvényként); ebben az egyszerű példában ez sem jelent problémát, nemsokára vissza is fogunk rá térni.
Felmerül a kérdés, hogy mit értünk precízen ,,jó’’ becslőfüggvény alatt. A gyakorlatban három tulajdonság különösen fontos:
- Elfogadjuk, hogy a becslőfüggvény által szolgáltatott becslés mintáról-mintára ingadozik, de legalább az teljesüljön, hogy az ingadozás centrumában a valódi (sokasági) jellemző legyen, olyan értelemben, hogy átlagosan jó legyen a becsült érték. Precízen: egy becslőfüggvényt torzítatlannak mondunk, ha a mintavételi eloszlásának a várható értéke a valódi (sokasági) jellemző. E tulajdonság neve: torzítatlanság. A fenti szimulációk azt sugallják, hogy az előbbi példában a mintaátlag torzítatlan becslője a sokasági várható értéknek (ezt persze még bizonyítani kellene).
- Ennek az ingadozásnak a mértéke lehetőleg minél kisebb legyen, e tulajdonság neve: hatásosság. A hatásosságot a mintavételi eloszlás szórásával mérhetjük, egy becslőfüggvényt hatásosnak mondunk, ha torzítatlan, és a torzítatlan becslők körében minimális szórású. A fenti szimulációk azt sugallják, hogy a mintanagyság növelésével egyre hatásosabbá válik a mintaátlag mint becslőfüggvény.
Azzal a kérdéssel, hogy hogyan lehet egy becslőfüggvényt ,,kitalálni’’ (tehát, ha megadnak egy paramétert, akkor mutatni egy rá vonatkozó, és persze lehetőleg minél jobb statisztikai tulajdonságokkal bíró becslőfüggvényt) nem foglalkozunk részletesebben, csak megemlítjük, hogy erre vonatkozóan jól bejáratott módszerek, ún. becslési elvek léteznek. (A legnevezetesebb közülük a maximum likelihood-elv, továbbá a plug-in becslés, a legkisebb négyzetek elve, a momentumok módszere és a Bayes-becslés.)
Nézzünk minderre egy példát! Tekintsünk egy (eloszlásával adott) sokaságot, mely \(X\sim\mathcal{N}\left(\mu,\sigma_0^2\right)\) eloszlást követ. (Tehát tetszőleges számú mintát vehetünk belőle; minden egyes ilyen mintaelem egy ilyen eloszlásból származó, egymástól független szám lesz.) Azt állítjuk (és ezt hamarosan szabatosabban is be fogjuk bizonyítani), hogy ekkor a belőle vett \(n\) elemű minták átlaga, azaz a \(\mu\) sokasági várható érték (mint sokasági jellemző) fenti becslőfüggvénye \(\overline{x}\sim\mathcal{N}\left(\mu,\sigma_0^2/n\right)\) eloszlást fog követni. (Tehát most feltételeztük, hogy azt a priori tudjuk, hogy normális eloszlású a sokaság, sőt, \(\sigma_0\)-t is ismertnek vesszük, azaz csak a \(\mu\) a kérdés.) Jegyezzük meg, hogy a sokasági jellemző, amit becsülni szeretnénk, itt a \(\mu\) maga; az tehát nem követ semmilyen eloszlást, egy – konstans – szám! (Csak mi nem ismerjük.) A következőkben ezt az állítást fogjuk matematikai úton, valószínűségszámítási eszközökkel bebizonyítani, mégpedig a legegyszerűbb esetre, a fent vázolt független és azonos eloszlású mintavételre.
Legyen az \(n\) elemű mintánk \(X_1,X_2,\ldots,X_n\sim\mathcal{N}\left(\mu,\sigma_0^2\right)\) függetlenül (mivel a mintavétel azonos eloszlású is, így mindegyik ugyanolyan eloszlást követ, ezért volt azt elég egyszer leírni). Figyeljük meg, hogy itt nagy betűket írtunk: ezek nem konkrét (realizálódott) értékek, hanem maguk is valószínűségi változók. (Most ugyanis statisztikai analízisét adjuk a helyzetnek: úgy képzeljük, hogy még nem vettünk mintát, hanem épp ellenkezőleg, azt vizsgáljuk, hogy ,,mi minden történhet’’ amikor majd mintát veszünk.) Ezzel a becslőfüggvényünk: \[ \overline{X}=\frac{\sum_{i=1}^n X_i}{n}. \]
Valószínűségszámításból tudjuk, hogy 1. Normális eloszlású valószínűségi változók összege normális (szépen megfogalmazva: a normális eloszláscsalád zárt a konvolúcióra). 2. A várható érték lineáris, így egy összeg várható értéke a várható értékek összege. 3. Ha ráadásul korrelálatlan (de csak ez esetben!), akkor a szórásnégyzetek – nem a szórások! – is összeadódnak. Ebből a háromból már következik, hogy \[ \sum_{i=1}^n X_i\sim\mathcal{N}\left(n\mu,n\sigma_0^2\right). \] Szintén valószínűségszámításból tudjuk, hogy \(\mathbb{E}\left(aX\right)=a \cdot \mathbb{E}X\) és \(\mathbb{D}^2\left(aX\right)=a^2 \cdot \mathbb{D}^2 X\), ezekből pedig már következik, hogy \[ \overline{X}=\frac{\sum_{i=1}^n X_i}{n} \sim \mathcal{N}\left(\mu,\sigma_0^2/n\right), \] ahogy azt eredetileg állítottuk is.
Ezzel igazoltuk, hogy ilyen körülmények mellett a mintaátlag torzítatlan becslője a sokasági átlagnak, sőt, kiszámoltuk a mintavételi szórását is. (Be lehetne látni kicsit komolyabb matematikai statisztikai eszközökkel, hogy ez ráadásul e körülmények között hatásos becslő is, tehát ennél kisebb mintavételi szórás el sem érhető a torzítatlan becslők körében.)
Ez tehát azt jelenti, hogy a 2944.5873016 gramm nem csak a születési tömegek átlaga (ahogy azt az előbb mondtuk), hanem egyúttal a ,,vizsgálat beválogatási feltételeinek megfelelő újszülöttek’’ (fiktív, végtelen!) sokaságának várható értékének becslője is! Nem csak azt mondhatjuk, hogy 2944.5873016 gramm a mintaátlag (biztosan), hanem azt is, hogy ez a legjobb tippünk arra, hogy mennyi a sokaság várható értéke. Vegyük észre, hogy minket valójában ez utóbbi érdekel! Tehát bár a számérték itt pont ugyanaz lett (ez nincs mindig így!), az igazán érdekes eredmény az utóbbi megfogalmazás (hiszen minket nem konkrétan ez a 189 újszülött érdekel, hanem általában az ilyen újszülöttek jellemzőinek viselkedése).
Mind ez idáig azonban csak olyan becslőfüggvényekről beszéltünk, melyek egyetlen értéket, ,,a’’ legjobb becslést adják vissza eredményként. Az ilyen becslést hívjuk pontbecslésnek. (Hiszen az eredménye egyetlen pont a számegyenesen.) Ez olyan szempontból azonban nem szerencsés, hogy az eredmény semmit nem mond az abban lévő bizonytalanságról – noha, legalábbis becsülni, azt is tudnánk!
Azt a becslési módszert, ami ezen túllép és explicite megjeleníti a becslésben lévő bizonytalanságot is, intervallumbecslésnek nevezzük. Az intervallumbecslés központi eszköze az konfidenciaintervallum (CI): ez egy olyan intervallum, melyre igaz, hogy a hogy ha sokszor megismételnék a mintavételt, és mindegyik mintából megszerkesztenénk a CI-t, akkor ezen CI-k várhatóan adott, nagy hányada (például 95%-a) tartalmazná az igazi (sokasági) értéket. Ez esetben ezt az intervallumot 95% megbízhatóság melletti konfidenciaintervallumnak nevezzük. A 95%, mint paraméter neve megbízhatósági szint, általában \(1-\alpha\)-nak nevezzük (tehát \(\alpha=0,\!05\) mellett beszélünk 95%-os megbízhatóságról). Első ránézésre kicsit furcsa lehet ez a jelölés, de majd a hipotézisvizsgálatnál is látni fogjuk, hogy \(\alpha\)-val valamilyen hibázás jellegű mennyiséget szeretnénk jelölni, nem jóságot.
Az induktív statisztikában tehát elfogadjuk (kénytelenek vagyunk elfogadni), hogy a becslésünk eredménye mintáról mintára változik, és így nem tudhatjuk biztosan, hogy adott mintából számolt becslés hogyan viszonyul a valódi (sokasági) értékhez – a konfidenciaintervallum azonban épp azt próbálja megragadni, hogy – adott minta alapján! – mire tippelhetünk, ,,vélhetően’’ hol lehet a valódi sokasági érték (adott, nagy megbízhatósággal). Ez természetesen már nem egyetlen szám, hanem egy tól-ig intervallum lesz a jellemzőre vonatkozóan. Hogy mit jelent a ,,vélhetően’’ és a ,,megbízhatóság’’, az pontosításra szorul, erre tárgyalásunk legvégén fogunk visszatérni.
Adott megbízhatósági szint mellett minél szűkebb a CI, annál kisebb a bizonytalanság a becslésünkben. Természetesen adott becslés mellett a CI szélességét a megbízhatósági szint fogja meghatározni: kis megbízhatóság mellett szűk intervallumot is mondhatunk, de ha nagy megbízhatóságra van szükségünk, akkor csak széles limiteket tudunk szabni. Itt tehát kompromisszumot kell kötnünk: az se jó, ha nagy biztonsággal tudjuk, hogy nem igazán tudjuk, hogy hol van az igazi érték, és az se, ha nagyon kis biztonsággal tudjuk, hogy igen pontosan hol van A 95% egy tipikus, gyakorlatban igen sokszor használt kompromisszum ez ügyben.
Nézzünk erre is egy számszerű példát! Folytatva előző példánkat, tudjuk, hogy \(\overline{X} \sim \mathcal{N}\left(\mu,\sigma_0^2/n\right)\). Ebből következik, hogy \[ \frac{\overline{X}-\mu}{\sigma_0/\sqrt{n}}\sim\mathcal{N}\left(0,1\right), \] azaz \[ \mathbb{P}\left(-z<\frac{\overline{X}-\mu}{\sigma_0/\sqrt{n}}<z\right)=\Phi\left(z\right)-\Phi\left(-z\right)=\Phi\left(z\right)-\left[1-\Phi\left(z\right)\right]=2\Phi\left(z\right)-1. \] Ha ezt a valószínűséget \(\left(1-\alpha\right)\)-nak választjuk (a megbízhatósági szint fenti értelme miatt), akkor kapjuk, hogy \(\Phi\left(z\right)=1-\frac{\alpha}{2}\) azaz \(z=\Phi^{-1}\left(1-\frac{\alpha}{2}\right)\). Erre a mennyiségre bevezetve a \(z_{1-\frac{\alpha}{2}}\) jelölést, rögtön látható, hogy a \(\left[\mu-z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}},\mu+z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}}\right]\) tartományba \(1-\alpha\) valószínűséggel esik \(\overline{X}\). Ezt nevezhetnénk ,,deduktív statisztikának’’, hiszen itt a sokaságot tekintettük ismertnek, és ez alapján következtettünk a minta viselkedésére.
Átrendezve ,,kapjuk’’ a minket érdeklő az induktív statisztikát: \[ \mathbb{P}\left(-z_{1-\frac{\alpha}{2}}<\frac{\overline{X}-\mu}{\sigma_0/\sqrt{n}}<z_{1-\frac{\alpha}{2}}\right)=1-\alpha \Rightarrow \mathbb{P}\left(\overline{X}-z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}}<\mu<\overline{X}+z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}}\right)=1-\alpha. \] Ekkor a konfidenciaintervallum immár egy konkrét mintára a fenti alapján: \[ \left[\overline{x}-z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}},\overline{x}+z_{1-\frac{\alpha}{2}}\frac{\sigma_0}{\sqrt{n}}\right]. \] Tipikusan \(\alpha=0,\!05\), amint mondtuk, ekkor \(1-\alpha=95\)%-os konfidenciaintervallumról beszélünk.
Nagyon fontos megfigyelni, hogy csak mintavétel előtt vannak valószínűségi változók (,,nagy betűk’), utána már nem (,,kis betűk
) – ezért használtuk a megbízhatóság szót a valószínűség helyett. Mintavétel után ugyanis már nem tehetünk olyan kijelentést, hogy a megkonstruált CI 95%-os ,,valószínűséggel
’ tartalmazza a valódi, sokasági paramétert, hiszen ha már egy realizálódott minta van a kezünkben, akkor elvileg akárhol lehet a valódi érték, erről semmi közelebbit nem tudunk mondani. Valószínűséget csak a (szükségképp képzeletbeli) ,,ismételt mintavételi’’ értelemben tudunk behozni a feladatba, ezért használjuk megkülönböztetésül a megbízhatóság szót. Így kell érteni, hogy a konfidenciaintervallum jellemzi, hogy ,,hol lehet’’ a valódi (sokasági) paraméter.
A születési tömegek 95%-os konfidenciaintervalluma [2840,0–3049,2] gramm. (Megjegyezzük, hogy ez a fentitől kissé eltérő módszerrel készült, ami tekintettel van arra is, hogy itt most – szemben a fenti példával – nem ismerjük a priori a sokaság szórását.) Ez azt jelenti, hogy a legjobb tippünk a születési tömeg sokasági várható értékére a 2944.5873016 gramm, de azt is tudjuk ezen felül mondani, hogy bár ez csak bizonytalan tipp (hiszen a becsült érték mintáról-mintára ingadozik), de 95%-os megbízhatósággal azért kijelenthető, hogy nem kisebb a keresett, ismeretlen sokasági várható érték mint 2840,0 gramm és nem nagyobb mint 3049,2 gramm. (Amit úgy értünk, hogy azt becsüljük, hogy ha a sokaságból 100 mintát vennénk, és mindegyikből ugyanígy megkonstruálnánk a konfidenciaintervallumokat, akkor várhatóan 95 esetben tartalmazná a CI a valódi, sokasági értéket.) Érdemes megfigyelni, hogy a konfidenciaintervallum két végpontja szimmetrikus a pontbecslésre; ez a várható érték becslésére jellemző, de más paramétereknél nem feltétlenül van így.
Itt is hasznos mindezeket egy szimulációval szemléltetni (4.3. ábra).
SimData <- data.frame( idx = 1:100, CI = t( replicate( 100, TeachingDemos::z.test( rnorm( 30, 70, 10 ), stdev = 10 )$conf.int ) ) )
ggplot(SimData, aes(xmin = CI.1, xmax = CI.2, y = idx)) + geom_linerange() +
geom_vline(xintercept = 70, color = "red") + labs(y = "")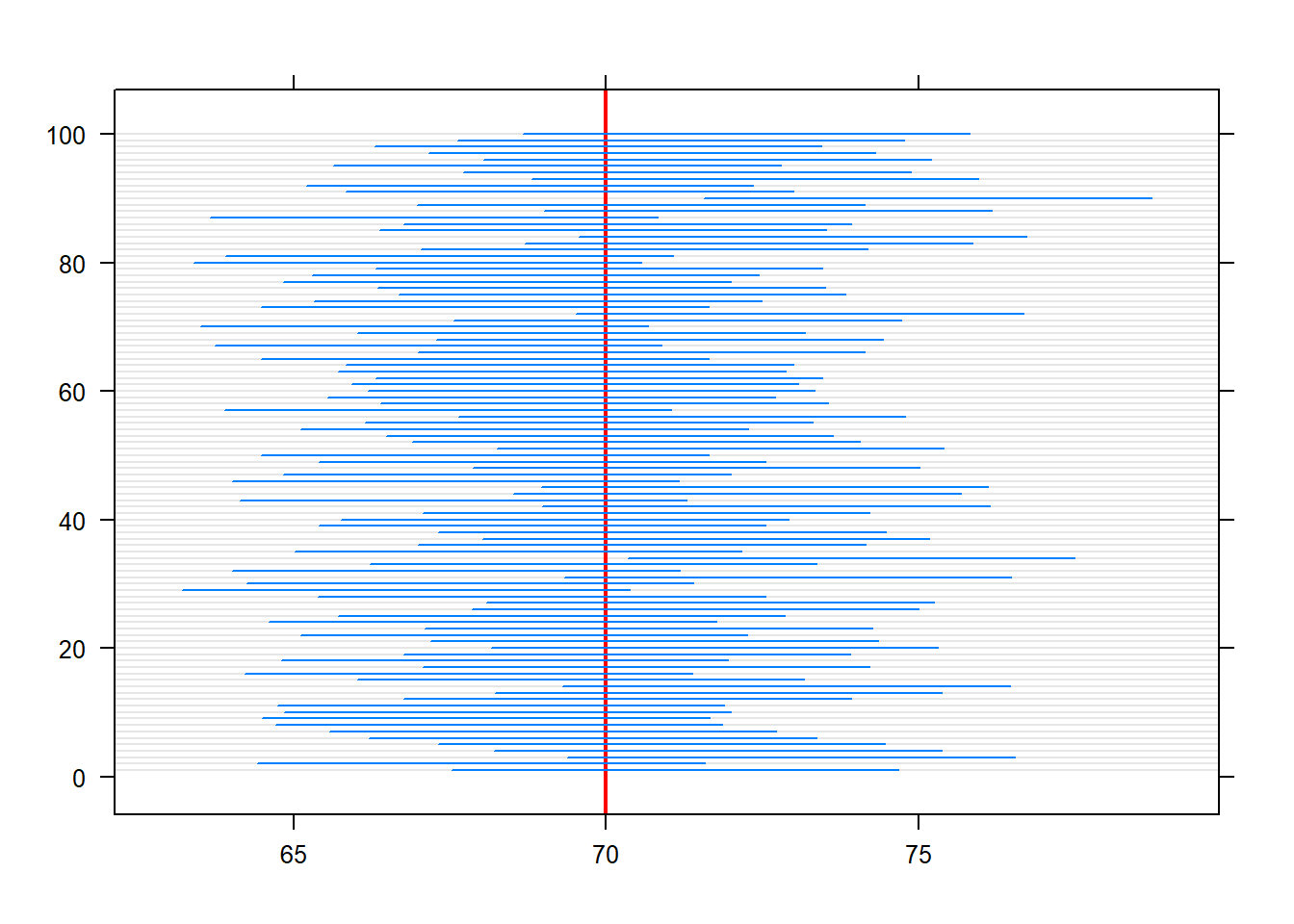
Ábra 4.3: Konfidenciaintervallumok szemléltetése szimulációval.
4.3 Hipotézisvizsgálat
Az induktív statisztika másik nagy ága a hipotézisvizsgálat. A hipotézisvizsgálat nagyon sok szempontból a becsléselmélet, ezen belül is az intervallumbecslés elméletének ikertestvére (ami ekvivalens, csak átfogalmazottan felírt egyenletekre vezet), mégis, saját szóhasználata, fogalomköre, és hatalmas gyakorlati jelentősége indokolja, hogy külön tárgyaljuk.
Amíg a becsléselmélettől azt vártuk, hogy nyilatkozzon egy számunkra ismeretlen jellemzőről, addig a hipotézisvizsgálat esetében van előzetes elképzelésünk a jellemző értékéről (például, hogy egy adott számmal egyenlő) – csak épp nem tudjuk, hogy ez igaz-e. Ha az előzetes feltevésünk mintára vonatkozna, akkor nem is volna semmi probléma: kiszámítjuk a jellemzőt a mintából, és megnézzük, hogy teljesült-e a feltevésünk. Mivel azonban a feltevés a sokaságra vonatkozik, így megint csak visszatérünk oda, hogy erről biztos döntést hozni lehetetlen minta alapján – de valószínűségit lehet. Nem tudjuk megmondani, hogy a sokaság átlagos testtömege 70 kg-e, ha a mintabeli átlag 65 kg de meg fogjuk tudni mondani (egyéb mintaadatok felhasználásával), hogy mennyire hihető, hogy 70 kg a sokasági átlag. Erre szolgál a hipotézisvizsgálat. Már most fontos megjegyezni, hog a hipotézisvizsgálat logikája bizonyos szempontból fordított: az előbbi kérdés ellentétére keresi a választ, arra, hogy ha 70 kg lenne a sokasági átlag, akkor mennyire lenne valószínű, hogy ettől olyannyira eltérő eredményt kapunk, mint a 65 (vagy annál is kisebb). Ha nagyon, akkor azt mondjuk, hogy ,,minden bizonnyal’’ nem 70 kg volt az átlag.
A problémát nyilván az adja, hogy – maradva a fenti példánál – nem tudhatjuk, hogy mi okozta ezt az 5 kg különbséget. Valójában tényleg 70 kg a sokaság átlaga, csak a mintavételi ingadozás játéka miatt pont olyan mintát fogtunk ki, amiben picit kisebb volt az átlag, vagy ez az 5 kg különbség olyan nagy, ami túlmutat a mintavételi ingadozáson, és azt kell feltételeznünk, hogy a hátterében sokasági hatás (is) van (tehát, hogy a sokasági átlag kisebb mint 70 kg)?
Amint a fentiekből is kiderült, a hipotézisvizsgálat mindig a sokaságra megfogalmazott állításból indul ki. Valójában nem is egy, hanem rögtön két állítást használ a hipotézisvizsgálat; nevük nullhipotézis (\(H_0\)) és ellenhipotézis (\(H_1\)) melyek jellemzően egymás komplementerei. (Azaz egymást kizárják, de a kettőből valamelyik biztosan fennáll.) A fenti példát így írhatnánk: \[\begin{align*} H_0&: \mu = \mu_0\\ H_1&: \mu \neq \mu_0\\ \end{align*}\] úgy, hogy \(\mu_0\)=70 kg.
Amit fontos észben tartani, hogy hipotézisvizsgálatnál az erős döntés mindig az elutasítás tud lenni, ezért a legtöbb próba úgy van megszerkesztve, hogy a szakmailag ,,izgalmas’’ állítás, a tudományos nóvum (hatásos a gyógyszer, van eltérés a laboreredményben stb.) az ellenhipotézisbe kerüljön. Pontosan emiatt az elutasítás esetén nagyon gyakran – szinonimaként – azt mondjuk, hogy a ,,próba szignifikáns’’.
A hipotézisvizsgálat központi eszköze a próbafüggvény (vagy más szóval tesztstatisztika). Az egész eszközt együtt tesztnek vagy próbának nevezzük. A próbafüggvény a mintaelemek függvénye, ilyen módon a próbafüggvénynek is eloszlása lesz. És itt jön a kulcs: a próbafüggvényt úgy választjuk meg, hogy \(H_0\) fennállása esetén valamilyen pontosan ismert eloszlást kövessen; ezt szokás nulleloszlásnak is nevezni. Természetesen a próbafüggvény konkrét értéke függeni fog a mintaelemektől, de az eloszlása nem függhet ettől (sem más, ismeretlen paramétertől, ha volna ilyen).
Hogy megértsük, hogy ez miért lesz alkalmas a hipotézispárról történő (valószínűségi) döntéshozatalra, nézzünk egy konkrét példát. Folytatva az előző példát, tegyük fel, hogy sokaságunk eloszlása normális, ismert szórással. Amint már megbeszéltük, ekkor \(\overline{X}= \sim \mathcal{N}\left(\mu,\sigma_0^2/n\right)\). Ez tehát a mintaelemek függvénye, és elvileg próbafüggvénynek is nevezhető, mert ha érvényesítjük rajta \(H_0\)-t (azaz \(H_0\)-t igaznak fogadjuk el), akkor azt kapjuk, hogy \(\overline{X}= \sim \mathcal{N}\left(\mu_0,\sigma_0^2/n\right)\), ami valóban már nem függ ismeretlen paramétertől. Ezzel, és a technikailag szintén megfelelő \(\overline{X}-\mu_0\sim \mathcal{N}\left(0,\sigma_0^2/n\right)\)-nel is az a gyakorlati baj azonban, hogy nagyon nehézkes lenne a használatuk, hiszen bár a nulleloszlás ismert, de minden \(\mu_0\)-ra, \(\sigma_0\)-ra és \(n\)-re más és más – azaz ezektől függően minden egyes hipotézisvizsgálathoz elő kéne keresni az adott eloszlást.
A \(\overline{X}-\mu_0\) azonban már mutatja az utat: próbálkozzunk a \(\frac{\overline{X}-\mu_0}{\sigma/\sqrt{n}}\) próbafüggvénnyel (jele általában \(Z\))! Ez már minden szempontból tökéletes lesz, hiszen nulleloszlása \(\mathcal{N}\left(0,1\right)\), azaz minden paramétertől függetlenül ugyanaz; egyetlen eloszlással elvégezhető az összes ilyen típusú hipotézisvizsgálat e körülmények között.
Foglaljuk össze hol tartunk! Konstruáltunk egy olyan függvényét a mintaelemeknek, melynek ismerjük az eloszlását ha fennáll a nullhipotézis. Ki tudjuk azt is számolni, hogy mennyi ennek a próbafüggvénynek az értéke a konkrét (realizálódott) mintánkból; ezt szokás empirikus értéknek (\(z_{\mathrm{emp}}\)) is nevezni. Innentől úgy okoskodhatunk: biztos döntést lehetetlen hozni (ez az előbbi példán nagyon jól látszik: a \(\mathcal{N}\left(0,1\right)\) nulleloszlás tartója az egész számegyenes, tehát még ha fenn is áll a nullhipotézis, elvileg akármilyen szám realizálódhat belőle, az elvileg bármilyen szám lehet a mintából kiszámított próbafüggvény értéke, azaz \(z_{\mathrm{emp}}\)), de mégis, mennyire hihető, hogy a szaggatott vonallal jelölt érték a folytonosan behúzott eloszlásból realizálódott a következő esetekben (4.4. ábra).
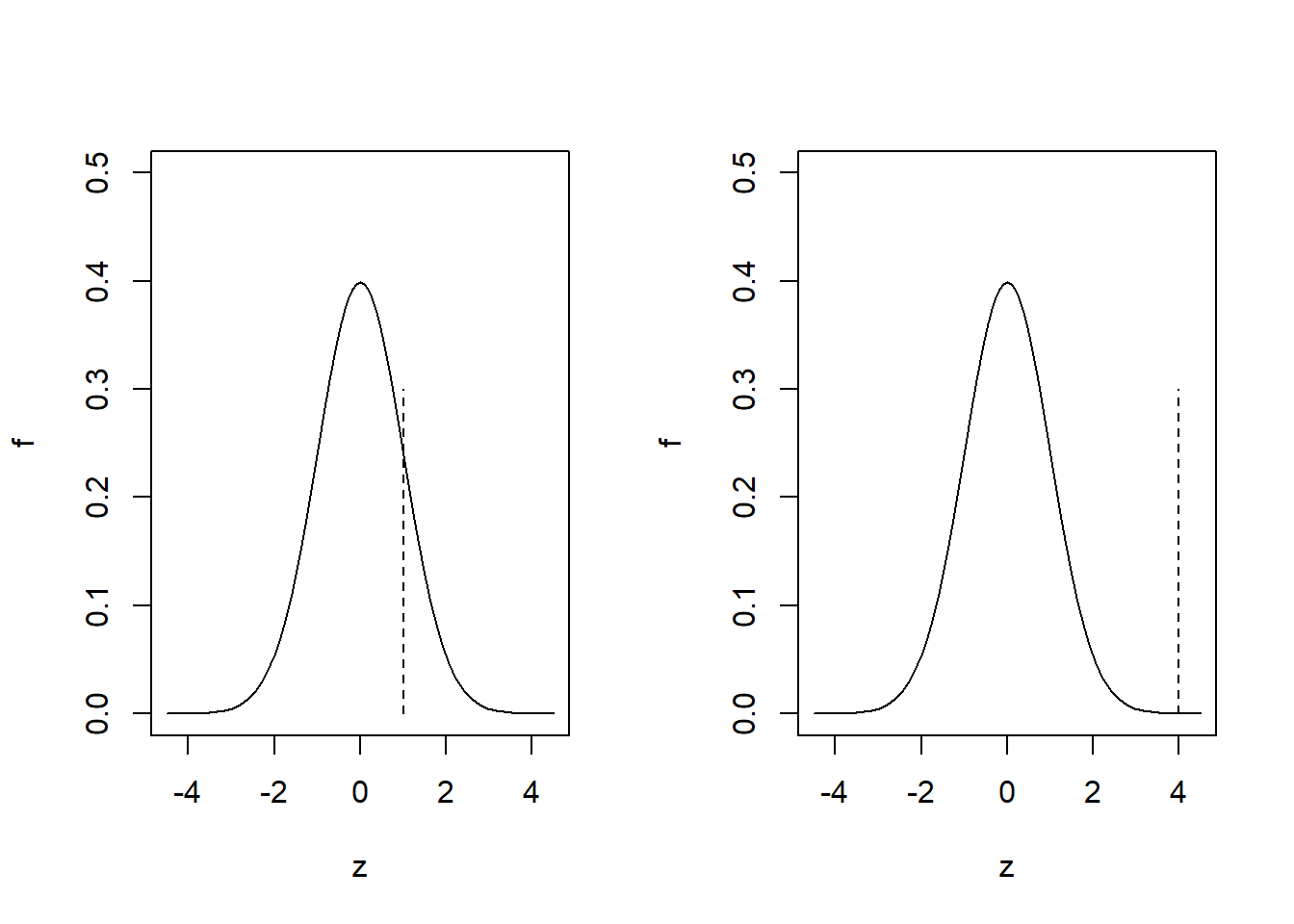
Ábra 4.4: A hipotézisvizsgálat alapgondolatának szemléltetése.
Érezhető, hogy bár elvileg mindkettő előfordulhat, de a bal oldalit hajlamosak vagyunk elhinni, a jobb oldalinál viszont épp ellenkezőleg, hajlunk arra, hogy azt gondoljuk, hogy az empirikus érték valójában más eloszlásból realizálódott. Noha elvileg a bal oldali is jöhet más eloszlásból, és a jobb oldali is ebből – ezért a bizonytalan megfogalmazások, mutatva, hogy ezek csak valószínűségi állítások.
Precízebben megfogalmazva: az kicsi valószínűségű esemény (\(\mathcal{N}\left(0,1\right)\) eloszlás esetén), hogy \(\pm 3\)-on kívül számot kapjunk. Ha mégis ilyen érték jön ki, akkor joggal kérdőjelezzük meg, hogy a próbafüggvény ilyen eloszlást követett – márpedig, ha fennáll a nullhipotézis, akkor ilyen eloszlást kellett követnie, így más szóval mi most arra következtettünk, hogy nem áll fenn a nullhipotézis!
Ez persze bizonytalan döntés, és itt jól látszik ennek az oka: nagyon is kijöhet \(\pm 3\)-on kívül szám még akkor is, ha fennáll a nullhipotézis, sőt, ennek a valószínűsége akár számszerűen is meghatározható (\(\Phi\left(-3\right)+\left[1-\Phi\left(3\right)\right]\) ami kb. 0,27%). Ha a \(\pm 3\)-on kívüli tartományra mondjuk az, hogy ide eső empirikus tesztstatisztika esetén ,,már nem hisszük el’’, hogy fennállt a nullhipotézis, akkor pontosan 0,27% valószínűséggel fogunk hibás döntést hozni: ekkora a valószínűsége ugyanis, hogy fennálló \(H_0\) esetén is ilyen extrém tesztstatisztika jöjjön ki.
Ha ez számunkra túl nagy, akkor megtehetjük, hogy mondjuk csak a \(\pm 4\)-en kívüli értékeket tekintjük ,,gyanúsnak’’ – csakhogy ekkor a valódi különbségek felderítését is megnehezítjük.
Az tehát egy kompromisszum eredménye, hogy ,,hol húzzuk meg a határt’’. A gyakorlatban ezt úgy hajtjuk végre, hogy az eloszlás legextrémebb, tehát a nullhipotézis fennállása esetén várt értéktől legtávolabb eső részein (a mostani példánkban: mindkét szélén szimmetrikusan) kijelölünk egy olyan tartományt, melynek egy adott, kicsi érték (jele \(\alpha\)) a valószínűsége13. Más szóval azt mondjuk, hogy ebbe az intervallumba elvileg ugyan eshet egy realizálódott érték akkor is, ha a nulleloszlás fennáll, de ennek olyan kicsi a valószínűsége, hogy ezt már nem tartjuk hihetőnek (hivatkozva arra, hogy ez a tartomány fekszik a legtávolabb nullhipotézis fennállása esetén várt értéktől). Tökéletesen látszik azonban, hogy csak bizonytalan döntést tudunk hozni: ez a kijelentésünk automatikusan az esetleges hibázás elfogadását jelenti – nagyon is tudjuk, hogy ebbe a tartományba eshet a realizálódott érték a nulleloszlás fennállása esetén is, mi mégis azt mondjuk, hogy ekkor már nem hisszük el a nullhipotézist. Mivel a normális eloszlás tartója az egész számegyenes, így egyértelmű, hogy ennél jobbat nem tudunk tenni, valahol korlátot kell húznunk.
Ilyen módon kijelöltük, hogy milyen empirikus tesztstatisztika-értékek esetén fogadjuk el a nullhipotézist (elfogadási tartomány), és milyenek esetén nem (elutasítási (vagy kritikus) tartomány). Látható, hogy a tartományok helyét az \(\alpha\) valószínűség szabja meg, ennek a valószínűségnek a neve: szignifikanciaszint.
Ebben a feladatban a túl magas és a túl alacsony tesztstatisztika érték is ugyanúgy az elvetés irányába mutat14, így az elfogadási tartományt valóban a nullára szimmetrikusan jelöljük ki. Ha például azt mondjuk, hogy a szignifikanciaszint 5%, azaz a legextrémebb 5%-nyi területen utasítsunk el, akkor azt úgy tehetjük meg, hogy a nulleloszlás alsó és a felső szélén is 2,5-2,5%-nyi valószínűséget vágunk le. Ezeket a ,,szétvágási pontokat’’, melyek az elutasítási és az elfogadási tartományokat határolják, kritikus értékeknek szokás nevezni. Mivel a nulleloszlás ismert, így ezek könnyen számszerűsíthetőek is mint a 0,025-ös és a 0,975-ös kvantilisei az eloszlásnak; például \(\alpha=5\)%-ra a két kritikus érték a \(c_a=-1,\!96\) alsó kritikus érték és a \(c_f=+1,\!96\) felső kritikus érték.
Mindezeket összefoglalóan szemlélteti @aref(fig:hiptartomanyok). ábra, \(\alpha=5\) és \(\alpha=1\)%-os szignifikanciaszintekre.
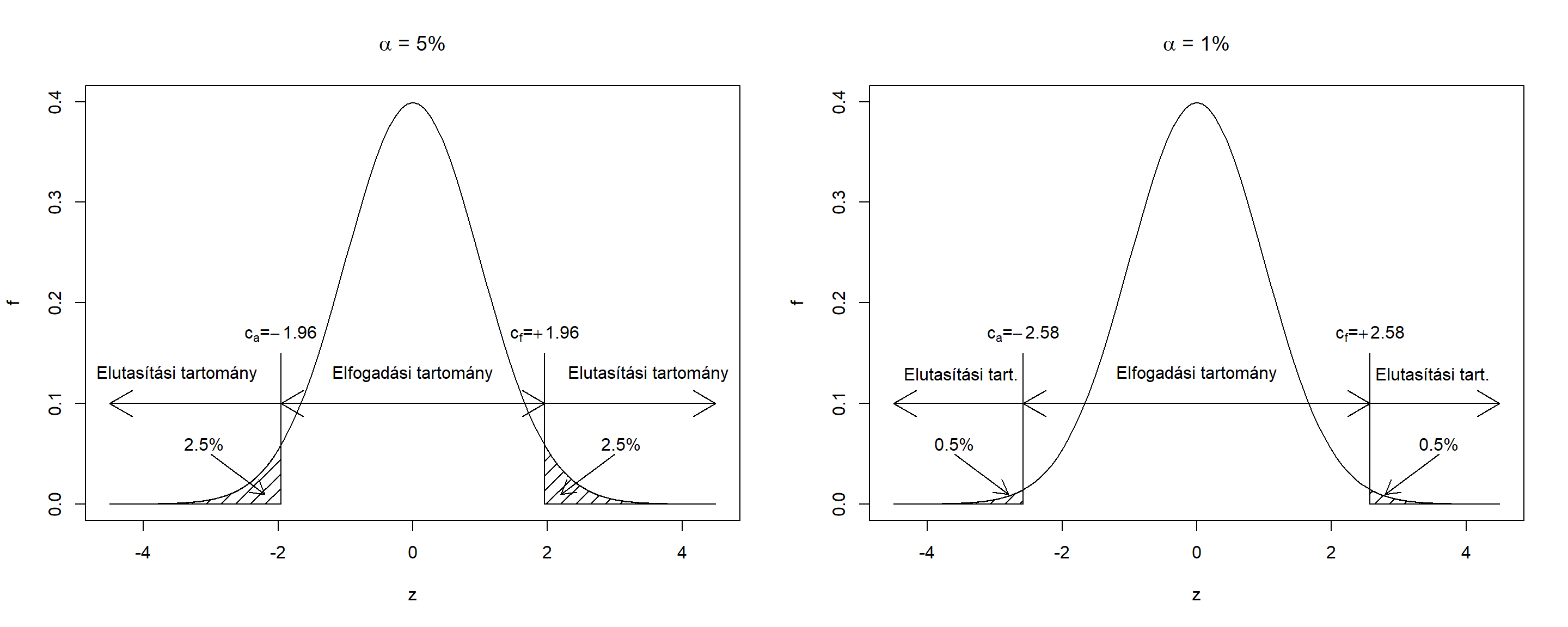
Ábra 4.5: A hipotézisvizsgálat döntésének szemléltetése két szignifikanciaszint mellett.
Amint arra már utaltunk is, \(\alpha\) beállításával a hipotézisvizsgálatban elkövethető kétféle hiba között egyensúlyozunk. Az egyik tévedési lehetőség, hogy fennáll a nullhipotézis, mi mégis elvetünk (ennek neve elsőfajú hiba; a valószínűsége felett nagyon is erős kontrollunk van, hiszen az épp \(\alpha\)); a másik hibázási lehetőség, hogy elvethetnénk a nullhipotézis, mi mégis elfogadunk (ennek neve másodfajú hiba, a valószínűségét \(\beta\)-val szokás jelölni; \(\beta\) értékét nem tudjuk jól kézben tartani, hiszen attól is függ, hogy konkrétan milyen ellenhipotézis áll fenn, amit általában mi sem tudhatunk). Ha \(\alpha\)-t növeljük (,,beljebb húzzuk’’ a kritikus értékeket, növeljük az elutasítási, csökkentjük az elfogadási tartomány méretét), akkor megemeljük a téves elutasítás, és lecsökkentjük a téves elfogadás valószínűségét, ha \(\alpha\)-t csökkentjük (,,kijjebb toljuk’’ a kritikus értékeket, növeljük az elfogadási, csökkentjük az elutasítási tartomány méretét), akkor megemeljük a téves elfogadás, és lecsökkentjük a téves elutasítás valószínűségét. Az \(\alpha=5\)% egy tipikus kompromisszum a kétféle hibázás között. Kiegészítésként megjegyezzük, hogy \(\left(1-\beta\right)\)-t a próba erejének szokás nevezni (hiszen azt mutatja meg, hogy ha a valóságban nem áll fenn a nullhipotézis, akkor azt mekkora valószínűséggel fogjuk detektálni).
A fentiekből is érezhető, hogy egy próba eredményének olyan formában történő megadása, hogy ,,5%-on szignifikáns’’ nem a legszerencsésebb, hiszen rögtön adódik a kérdés: vajon 1%-on is szignifikáns lett volna? És 0,1%-on? Nem mindegy, hiszen egy olyan eredmény, mely 5%-on szignifikáns, de 4%-on nem, sokkal nagyobb bizonytalanságú, mint egy olyan, ami 0,1%-on is szignifikáns. Megoldás lehetne a tesztstatisztika konkrét értékének megadása, ez azonban gyakorlati szempontból nehézkes, hiszen így minden esetben meg kéne nézni, hogy mi a nulleloszlás (hiszen a tesztstatisztika empirikus értékét muszáj ahhoz viszonyítani). Éppen ezért a mai gyakorlatban inkább azt adják meg, hogy melyik lenne az a szignifikanciaszint, ami mellett a tesztstatisztika empirikus értéke épp az elutasítás és az elfogadás határa kerülne. Ennek neve: \(p\)-érték (vagy empirikus szignifikanciaszint). Például, gondoljuk azt, hogy próbánk 5%-on elutasít. Ekkor elkezdjük az \(\alpha\)-t csökkenteni (ezzel kijjebb húzzuk a kritikus értékeket, bővítjük az elfogadási, szűkítjük az elutasítási tartomány). Elérjük a 4%-ot, az empirikus tesztstatisztikánk még mindig az elutasítási tartományban van, tovább csökkentjük az \(\alpha\)-t, és így tovább míg nem egyszer csak azt vesszük észre, hogy mondjuk 2,31%-on még elutasít a teszt, de 2,29%-on már nem. Ekkor azt mondjuk, hogy a teszt \(p\)-értéke 2,3%.
A \(p\)-érték tehát nem más, mint a szignifikanciaszint akkor, ha a megfelelő (alsó vagy felső) kritikus értéket a tesztstatisztika empirikus értékének helyére helyezzük át. (A másikat pedig, értelemszerűen, az ellentétére, hiszen a kritikus értékek ebben ez esetben – ahogy már megbeszéltük – szimmetrikusak.) Ebből az is következik, hogy a \(p\)-érték számszerűen a nulleloszlás integrálja az empirikus tesztstatisztikától extrémebb irányba (illetve ennek kétszerese), ugyanúgy, ahogy az \(\alpha\) is – definíció szerint – a nulleloszlás integrálja a kritikus értékektől extrémebb irányokba (és itt, ahogy megbeszéltük, a kritikus érték szerepét az empirikus tesztstatisztika játssza). Ennek meghatározása tehát manapság már számítástechnikai szempontból is problémamentes.
Világos, hogy \(p\)-érték az elvetésben való bizonyosságunkat fejezi ki. Ez az eredményközlés azért rendkívül praktikus, mert – szemben az előzőekkel – az olvasó ,,elvégezheti magának’’ a hipotézisvizsgálatot, és bármilyen szignifikanciaszinten döntést hozhat. A \(p\)-értéknél magasabb szignifikanciaszinteken elutasítás lesz a döntés (ekkor bővebb az elutasítási tartomány, bele fog esni az empirikus tesztstatisztika), a \(p\)-értéknél alacsonyabb szinteken pedig elfogadás (az elutasítási tartomány szűkebb, az empirikus tesztstatisztika az elfogadási tartományba fog esni).
Végezetül egy fontos gyakorlati kérdésre hívjuk fel a figyelmet. Amint már megbeszéltük, az \(\alpha\) azt mutatja meg, hogy egy adott próba mekkora valószínűséggel ad téves jelzést. (Emlékezzünk rá, hogy általában mi az elutasítást keressük!) Igen ám, de ha mi két próbát végzünk egymástól függetlenül úgy, hogy akkor is találatot deklarálunk, ha legalább az egyik teszt szignifikáns lett, akkor valójában már nem \(\alpha\) valószínűséggel kapunk jelzést akkor is, ha nincs hatás (egyik esetben sem), hanem \(1-\left(1-\alpha\right)^2\) valószínűséggel! (Hiszen a hibás jelzés annak a komplementere, hogy mindkét teszt jó döntés ad, mivel pedig függetlenek, ezek valószínűsége összeszorzódik.) Ez pedig nagyon nem mindegy, a tipikus \(\alpha=5\)%-ra ez a valószínűség már 9,75%! Tehát valójában majdnem a nominális szignifikanciaszint kétszerese lesz annak a valószínűsége, hogy kapunk elutasítást – miközben a valóságban nincs is hatás egyik esetben sem! Ezt a jelenséget szokás \(\alpha\)-inflációnak nevezni. (A kétféle \(\alpha\)-t pedig néha megkülönböztetésül comparisonwise (\(\alpha_C\)) \(\alpha\)-nak illetve familywise (\(\alpha_F\)) \(\alpha\)-nak nevezik. Az előbbi annak a valószínűsége, hogy egy teszt hibás jelzést ad (ez az eddig tárgyalt \(\alpha\)), az utóbbi annak a valószínűsége, hogy tesztek egy családjából legalább egy lesz, ami hibás jelzést ad.) Az összefüggés a kettő között tehát: \[ \alpha_F = 1-\left(1-\alpha_C\right)^k, \] ahol \(k\) az elvégzett próbák száma.
Azt a helyzetet, amikor egymással párhuzamosan több, egymástól független hipotézisvizsgálatot futtatunk (és vagylagosan keresünk szignifikáns eredményt), többszörös összehasonlítások helyzetének szokás nevezni.
A dolog azt sugallja számunkra, hogy ha sok tesztet végzünk párhuzamosan, akkor valamit tenni kell az ellen, hogy ne találjuk túl könnyen fals elutasításokat. A legegyszerűbb megoldás, ha a tesztenkénti (comparisonwise) szignifikanciaszintet lecsökkentjük. Például, az ún. Bonferroni-egyenlőtlenség szerint \(1-\left(1-\alpha\right)^k\leq \alpha\cdot k\), ezért durva becsléssel úgy korrigálhatjuk a szignifikanciaszintet, hogy elosztjuk a célszintet az elvégzett hipotézisvizsgálatok számával. Ez garantálja, hogy a \(k\) teszt elvégzését együttesen tekintve sem lehet a kitűzött szignifikanciaszint feletti az elsőfajú hibák aránya.
A módszer hátránya, hogy túl drasztikus: annyira megnehezíti a nullhipotézis elvetését, hogy a valós különbségek is ,,el fognak veszni’’. Vannak módszerek, melyek ezt enyhítik (pl. Holm–Bonferroni-korrekció), illetve melyek teljesen más elven próbálják elérni az \(\alpha\)-infláció enyhítését (pl. FDR). Ennek a kérdéskörnek például a microarray adatok kiértékelése kapcsán (ahol elképesztő mennyiségű tesztet kell függetlenül végezni) nagyon megnőtt a jelentősége; ettől eltekintve azonban az orvosok általában nem viszik túlzásba a védekezést ez ellen
Itt hívjuk fel a figyelmet az ún. szignifikanciavadászat jelenségére. Ez lényegében nem más, mint a többszörös összehasonlítások helyzetének rosszindulatú kiaknázása inkorrekt következtetésre. A szignifikanciavadászat jelenségét inkább egy példával illusztráljuk: tegyük fel, hogy bizonyítani akarjuk, hogy a hétfőn és kedden született emberek laboreredményei között szignifikáns eltérés van. Bár ez ránézésre látható módon abszurdum, a fentiek kihasználásával tulajdonképpen nem is nehéz bizonyítani: manapság már a rutinszerűen vizsgált laborparaméterek száma is eléri a 20-30-at, így nincs más dolgunk, mint mindegyiket összehasonlítani! Természetesen valós különbség sehol nem lesz, de mivel 5% valószínűséggel mindegyik adhat téves jelzést, így 30 között már az lenne a meglepő, ha nem kapnánk egyetlen elutasítást sem. Ha a vizsgálatot – korrekt módon – úgy publikáljuk le, hogy összehasonlítottunk 30 laborváltozót 5%-on, és közülük 1 esetben, az XYZ-nél szignifikáns különbséget találtunk, akkor mindenki rögtön tudni fogja, hogy mi történt (azaz, hogy nem jelenthetjük ki, hogy találtunk bármit is). Igen ám, de ha inkorrekt módon játszunk, akkor azt tesszük, hogy a cikket úgy írjuk meg, hogy mi előre tudtuk, hogy XYZ-ben lesz különbség (mert van egy ragyogó kórélettani modellünk, mely az XYZ termelését a születés napjával hozza összefüggésbe), és ezért célirányosan XYZ-t leteszteltük, és lám: valóban szignifikáns különbséget is kaptunk! Ezzel szemben nehéz védekezni, hiszen magából az eredményközlésből nem lehet rájönni, hogy mi történt (de természetesen a vizsgálat reprodukciója azonnal lebuktatja a csalást).
Zárásként részletesebb indoklás nélkül felhívjuk három összefüggésre a figyelmet.
- Nagyon fontos gyakorlati probléma, hogy adott feladat vizsgálatára konkrétan melyik próbát használjuk. Ez közel sem triviális kérdéskör, ugyanis a feladat önmagában még nem determinálja a próbát: sok feladat van, amire akár tucatnyi különböző próba is elérhető; ezek tipikusan az előfeltevéseikben különböznek. (Azaz, hogy milyen a priori megkötésekkel élnek a sokaságra vonatkozóan.) Ennek kapcsán arra hívjuk fel a figyelmet, hogy egyrészt ha egy próba előfeltevései nem teljesülnek, de mi mégis alkalmazzuk, akkor nem garantált, hogy valid végeredményt kapunk, másrészt viszont a több előfeltevésre építő próbáknak általában kisebb az erejük. A tanulság, hogy mindig annyi előfeltevésre építő próbát használjunk, amennyit tudunk, se többet se kevesebbet: amely előfeltevésekről tudjuk, hogy teljesülnek (a priori!) azokat építsük be a próbaválasztásba de többet ne.
- Rögtön itt érdemes megjegyezni, hogy – bár egyes statisztikai programcsomagok notóriusan az ellenkezőjét sugallják – elvileg nem illik az alapján dönteni, hogy milyen próbát használunk, hogy az előfeltevéseit ugyanazon mintán egy másik próbával leellenőrizzük. Ezért hangsúlyoztuk az előbbi pontban, hogy a feltevésekről a priori kell döntenünk (korábbi eredmény, másik mintán végzett teszt stb. alapján).
- Végül felhívjuk a figyelmet, hogy egy próba erejét önmagában növeli a nagyobb mintanagyság. Pontosan ezért a klasszikus mondás szerint: ,,kis hatás kimutatásához nagy minta kell, nagy hatáshoz elég a kisebb minta is!’’.
Mutatunk egy példát a hipotézisvizsgálat alkalmazására is: vizsgáljuk meg azt a kérdést, hogy a dohányzó anyák újszülötteinek születési tömege eltér-e a nemdohányzó anyák újszülötteitől!
Az első kérdés, hogy mit értünk az alatt, hogy ,,eltér’’. Ezt többféleképp is lehetne operacionalizálni, most maradjunk annál a – kézenfekvő, és klinikailag is releváns – megközelítésnél, hogy a várható születési tömegük kisebb-e. (Tehát a kérdést a várható értékek egyezésére hegyezzük ki, nem az érdekel minket, hogy például a szórása a születési tömegeknek eltér-e a két csoportban.)
Az adatbázisban 115 nemdohányzó és 74 dohányzó anyától származó újszülött van. Gyorsan kiszámolhatjuk, hogy az előbbi csoportban az újszülöttek átlagos születési tömege 3055,7 gramm, míg az utóbbiban 2771,9 gramm. Mondhatjuk akkor, hogy a dohányzó anyák újszülöttjei kisebb tömegűek? Természetesen nem! Ez ugyanis csak annyit mondott, hogy a mintában kisebb a tömegük, de minket természetesen nem a konkrét minta érdekel, hanem a sokaság! Kijelenthetjük ez alapján, hogy a sokaságban is kisebb a dohányzó anyák újszülöttjeinek a várható születési tömege? Nem, a helyzet nem ilyen egyszerű: elképzelhető, hogy mindkét csoportnak ugyanannyi (a sokaságban!) a várható születési tömege, csak épp pont olyan mintát vettünk, amiben a dohányzó anyáknál ez kisebb. (Ez természetesen tökéletes mintavétel esetén is előfordulhat – mintavételi ingadozás, ugyebár!) Sőt, akár az is lehet, hogy épp a dohányzó anyák újszülöttei nagyobb születési súlyúak várhatóan, csak a mintavétel ördöge az ő csoportjukból pont kicsi, a nemdohányzó csoportból meg nagyobb újszülötteket dobott ki.
A kérdésről tehát biztosat nem lehet mondani – de statisztikai próbával valószínűségi kijelentést tehetünk. Elsőként döntenünk kell arról, hogy milyen próbát alkalmazzunk. Ennek a részletei számunkra most nem fontosak, a lényeg csak a végeredmény: a körülmények (két független csoport, aránylag nagy mintanagyság mindkét csoportban, a priori nem ismert sokasági szórás) a választásunk az ún. Welch-próbára esik. Ennek nullhipotézise, hogy a két csoport várható értéke között nincs különbség, ellenhipotézise, hogy van, a két várható érték nem egyezik.
Végezzük el a próbát:
##
## Welch Two Sample t-test
##
## data: bwt by smoke
## t = 2.7299, df = 170.1, p-value = 0.007003
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## 78.57486 488.97860
## sample estimates:
## mean in group 0 mean in group 1
## 3055.696 2771.919A \(p\)-érték: \(p=0,\!007\), ez minden szokásos szignifikanciaszintnél kisebb (még az 1%-ot sem éri el), így kijelenthetjük: a várható értékek egyezésére vonatkozó nullhipotézis minden szokásos szignifikanciaszinten elvethető, azaz minden szokásos szignifikanciaszinten kijelenthető, hogy a két csoport (sokaságbeli!) várható értéke között különbség van. (Azaz: a mintában tapasztalt különbség olyan nagy (a minta egyéb jellemzőit is figyelembe véve), hogy az már túlmutat a mintavételi ingadozás hatásán, nem hihető, hogy betudható pusztán a mintavételi ingadozás hatásának. Azt kell feltételeznünk, hogy mögötte sokasági hatás (azaz sokaságban is eltérő várható érték) van.)
Mindezt röviden úgy is megfogalmazhatjuk, hogy a különbség szignifikáns, még más szóval, hogy a két csoport között lényeges különbség van. (Ebben a kontextusban a ,,lényeges’’ statisztikai értelemben szignifikánsat jelent.) Ez a jó pont arra, hogy felhívjuk a figyelmet a különbségre a – most definiált – statisztikai szignifikancia és a – köznapi értelmű – klinikai szignifikancia között. E kettőt mindig szigorúan különböztessük meg egymástól! A köznapi szóhasználatban a ,,lényeges különbség’’ alatt ugyanis azt értjük, hogy a tárgyterületi (esetünkben: orvosi) skálán mi bír jelentőséggel. 1 grammal nagyobb születési tömegnek semmi (klinikai) jelentősége (nem gondol az orvos más klinikai helyzetre, nem rendel más vizsgálat, más kezelést stb.), 500 grammnak nagyon is lehet. A statisztikai szignifikancia viszont teljesen mást mér: azt, hogy mennyire hihető, hogy a különbség betudható a mintavételi ingadozásnak! Adott esetben lehet 500 gramm különbség is (statisztikailag) inszignifikáns (ha nagy a szórás, vagy kicsi a mintanagyság), és lehet 1 gramm különbség is (statisztikailag) szignifikáns (ha kicsi a szórás, vagy nagy a mintanagyság).
Biztos ez a döntés? Természetesen nem! Bár a \(p\)-érték nagyon alacsony, de mivel nem nulla (soha nem is lehet az), így épp azt mutatja, hogy a döntésünkben mekkora bizonytalanság van – mert van benne.
Ebbe természetesen beletartozhat több jellemző egyszerre történő becslése is, mi most azonban az ún. egydimenziós paraméterbecslésekre fogjuk korlátozni magunkat.↩︎
Átlagról általában akkor beszélünk, amikor a sokaság véges, ilyenkor tipikusan úgy képzeljük (,,elemeivel adott sokaság’
), hogy a sokaságot véges sok érték felsorolásával megadhatjuk; várható értéket általában akkor mondjuk, ha a sokaság fiktív, végtelen, ilyen tipikusan úgy gondoljuk (,,eloszlásával adott sokaság
’), hogy azt a háttéreloszlást ismerjük, melyet a sokaság minden egyes eleme követ, legegyszerűbb esetben független és azonos eloszlású módon.↩︎Egy tartomány valószínűsége alatt most azt értjük, hogy adott eloszlás mellett mekkora annak a valószínűsége, hogy az eloszlásból realizálódott érték a tartományba esik, azaz mennyi a sűrűségfüggvény integrálja a tartomány felett.↩︎
Ez nem szükségszerű, a hipotézispár függvényében léteznek ún. egyoldali próbák is, de ezzel most nem foglalkozunk.↩︎